模型评估指标
混淆矩阵 Confusion matrix
| 预测1 | 预测0 | 合计 | |
|---|---|---|---|
| 实际1 | TP(True Positive) | FN(False Negative) | Actual Positive |
| 实际0 | FP(False Positive) | TN(True Negative) | Actual Negative |
| 合计 | Predicted Positive | Predicted Negative | All |
- Recall(召回率), Sensitivity(敏感性): TP / (TP + FN)
- Precision(精确率): TP / (TP + FP)
- Specificity(特异性): TN / (TN + FP)
- Accuracy(准确率): (TP + TN) / (TP + FP + FN + TN)
- F值:F-measure = 2 (Recall Precision) / (Recall + Precision)
- 加权调和平均数,假设Precision和Recall同样重要
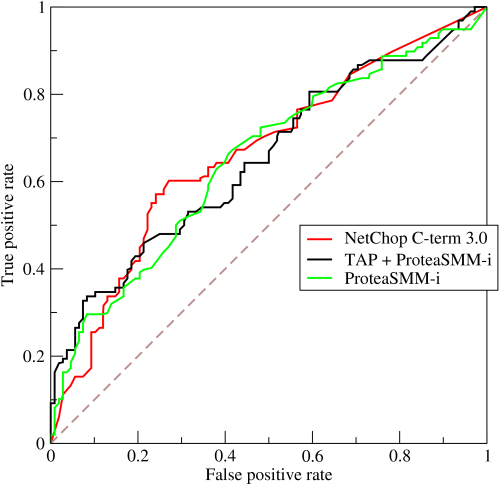
ROC和AUC
ROC(Receiver Operating Characteristic)曲线和AUC(Area Under Curve)常被用来评价一个二值分类器(binary classifier)的优劣。
ROC
ROC曲线的横坐标为false positive rate(FPR),纵坐标为true positive rate(TPR)。
FPR = 1- Specificity = FP / N = FP / (TN + FP)
TPR = Recall = Sensitivity = TP / P = TP / (TP + FN)
- (0,1):FPR=0,TPR=1,即FP和FN都为0,所有分类都正确。
- (1,0):FPR=1,TPR=0,即FP和FN都为1,所有分类都错误。
- (0,0):FPR=0,TPR=0,即FP为0,FN为1,所有分类预测为负样本。
- (1,1):FPR=1,TPR=1,即FP为1,FN为0,所有分类预测为正样本。
- y=x线上:采用随机分类的分类器。
- ROC曲线越接近左上角,该分类器性能越好。
ROC曲线的优点:当测试集中的正负样本的分布变化的时候,ROC曲线能够保持不变。在实际的数据集中经常会出现类不平衡(class imbalance)现象,即负样本比正样本多很多(或者相反),而且测试数据中的正负样本的分布也可能随着时间变化。
AUC
AUC(Area Under Curve)被定义为ROC曲线下的面积。由于ROC曲线一般都处于y=x这条直线的上方,所以AUC的取值范围在0.5和1之间。
The AUC value is equivalent to the probability that a randomly chosen positive example is ranked higher than a randomly chosen negative example.
AUC值越大,当前分类算法越可能将正样本排在负样本之前,即能更好的分类。
Lift
Lift = [TP/(TP+FP)] / [(TP+FN)/(TP + FP + TN + FN)]
用于衡量与不利用模型相比,模型预测能力的提升度。Lift越大,模型效果越好。
在不使用模型时(baseline model),需要在整个样本中挑选,挑选的准确率是(TP+FN)/(TP + FP + TN + FN)。
在使用模型时,,只在预测为positive的样例中挑选,挑选的准确率是TP/(TP+FP)。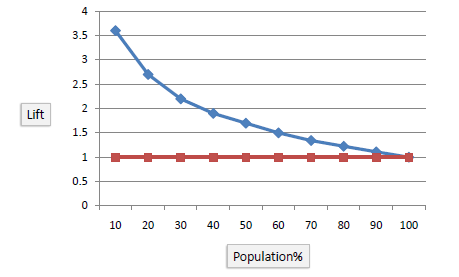
当阈值越大,越少的观测值会归为正例,但这部分越具有正例特征(以银行向客户推荐信用卡的例子来看,这一部分人群对推荐的反应最为活跃),所以在这个设置下,对应的lift值最大。当阈值越小,越多的观测值会归为正例,这时分类的效果就跟baseline model差不多了,相对应的lift值就接近于1。
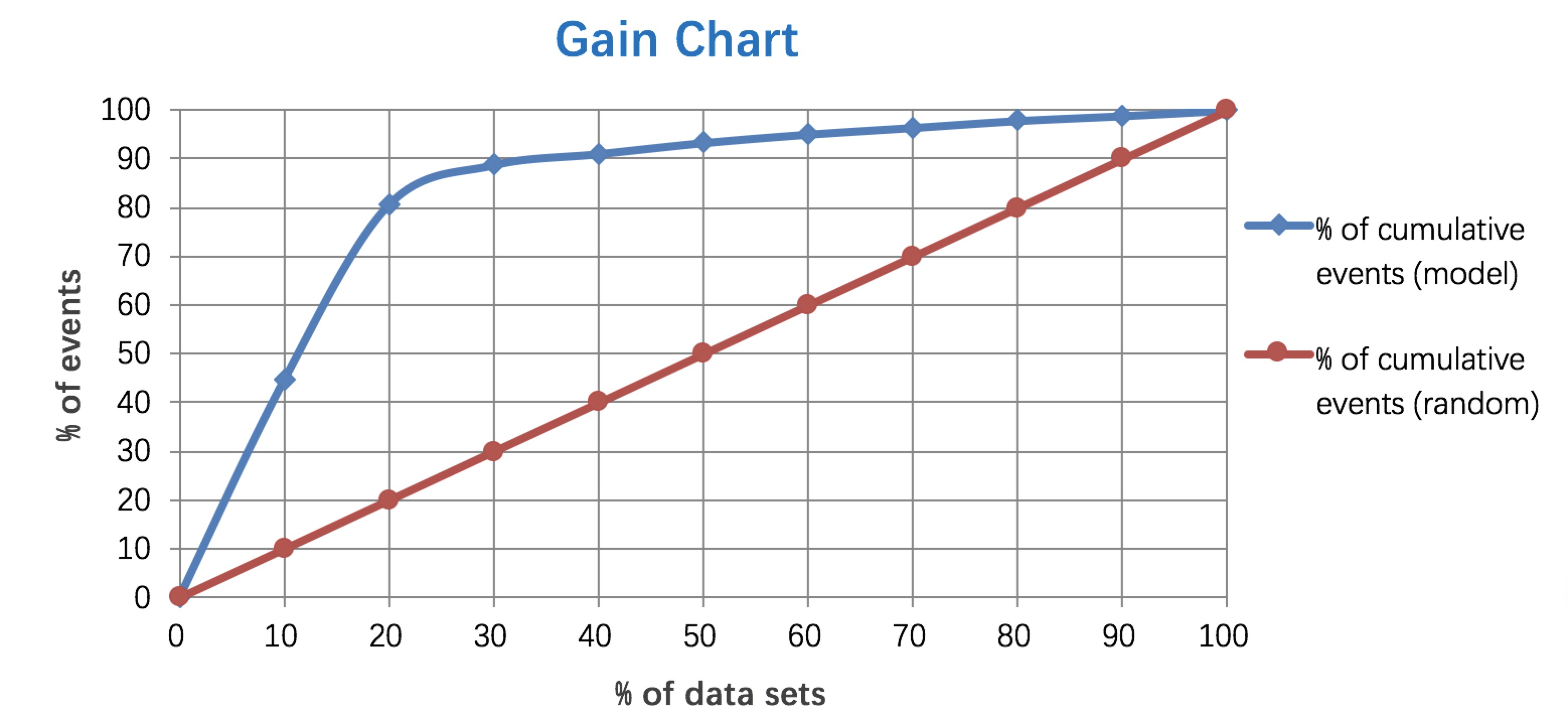
Gain
增益图与提升图的区别在于纵坐标。它的纵坐标是TP/(TP+FP)。
增益图是描述整体精准率的指标。按照模型预测出的概率从高到低排列,将每一个百分位数内的精准率指标标注在图形区域内,就形成了非累积的增益图。如果对每一个百分位及其之前的精准率求和,并将值标注在图形区域内,则形成累积的增益图。
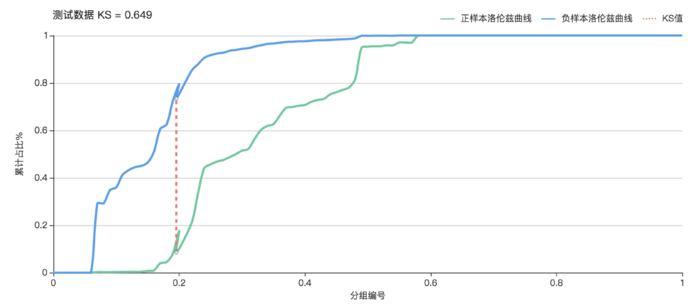
K-S
正样本洛伦兹曲线记为f(x),负样本洛伦兹曲线记为g(x),K-S曲线实际上是f(x)与g(x)的差值曲线。K-S曲线的最高点(最大值)定义为KS值,KS值越大,模型分值的区分度越好,KS值为0代表是最没有区分度的随机模型。准确的来说,K-S是用来度量阳性与阴性分类区分程度的。
K-S曲线的纵坐标是TPR与FPR。